
E01: Transformer之后?DeepSeeK 26年元旦最新论文解读
SEED· AI主题分享第1期
分享人:@小明
日期: 2026-01-03 20:30
录制文件:https://meeting.tencent.com/crm/N1x6vE8Md9
密码:SWCG
总结:
本次分享介绍了DeepSeek最新论文针对“HyperConnection”结构的优化方案,并深入探讨了算法稳定性、算子工程优化及后续发展潜力。
1. DeepSeek模型优化的核心思想
驱动力:在算法设计上进行微小改动(如修改公式),核心目标是解决模型在特定硬件(GPU)上部署时的稳定性、效率和成本问题。
方法论:采用“解谜游戏”视角,将复杂的系统优化问题拆解为算子设计、存储管理、调度策略等多个步骤逐一攻克,确保模型既能进行大规模稳定训练,又能高效运行。
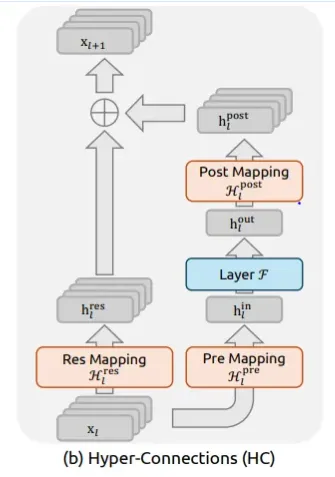
2. 模型架构优化(HyperConnection vs ResNet/H-Self-Attention)
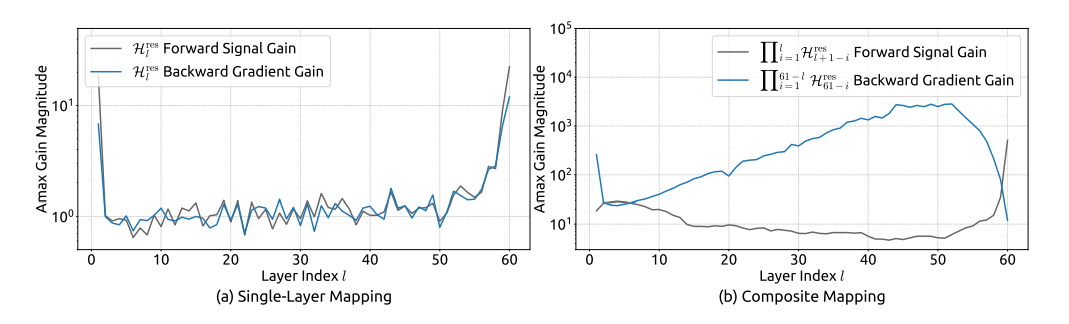
Problem: DeepSeek在优化H-Connection(类似H-Self-Attention)结构时发现,其内部参数矩阵(H矩阵)可能导致梯度爆炸,影响模型训练的稳定性。
Solution: 引入Manifold Jam(流形约简)技术对H矩阵施加约束。该技术通过复杂的数学变换,确保矩阵的行列式范数小于等于1,从而有效地抑制了梯度爆炸风险,使模型更加稳定。
数据支持: 通过消融实验验证了该方法的有效性,移除H矩阵后模型loss上升了2%,而加入H矩阵后,整体效果改善了2%。
3. 工程实现优化
算子设计: DeepSeek会对模型中每个算子进行详细分析,评估其计算成本和数据依赖(输入/输出),以优化算子的合并与拆分,减少冗余计算和数据传输。
存储策略: 采用“能重算则不缓存”的原则,把中间的全零矩阵和激活层等功能性属性(如投影)缓存,而不是那些可以通过重计算得到的值,以降低对昂贵全局内存(GPU Global Memory)的访问压力。
调度与并行: 设计了支持高优先级任务(如主干路径)与普通任务混合调度的工作流,利用多个stream(队列)并行处理,以减少计算等待时间。
4. 对业界的潜在影响
DeepSeek的工程优化思路表明,仅通过提升模型训练的稳定性与可扩展性,便能在不依赖复杂算法创新的前提下,以更低的成本和更合适的硬件训练出高性能模型。此举可能为业界提供新的技术方向和参考。
笔记:
教学关卡:深度学习的网络连接
深度学习基本说明书
核心:通过前向传播算出一个残差(forward),再通过后向(反向)传播(backward),更新每个节点的权重,让输出尽可能接近想要学习的内容
结构
原始结构 |
|
Resnet |
|
HC(hyper connection) |
|
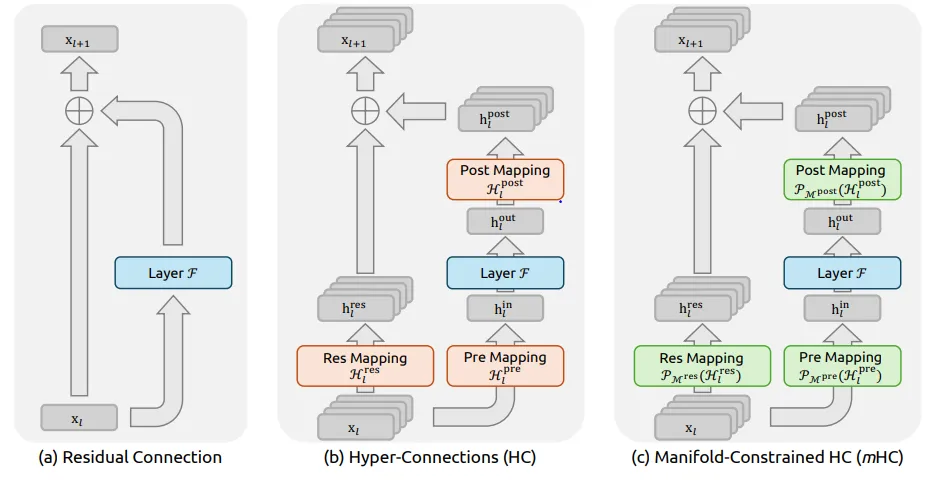
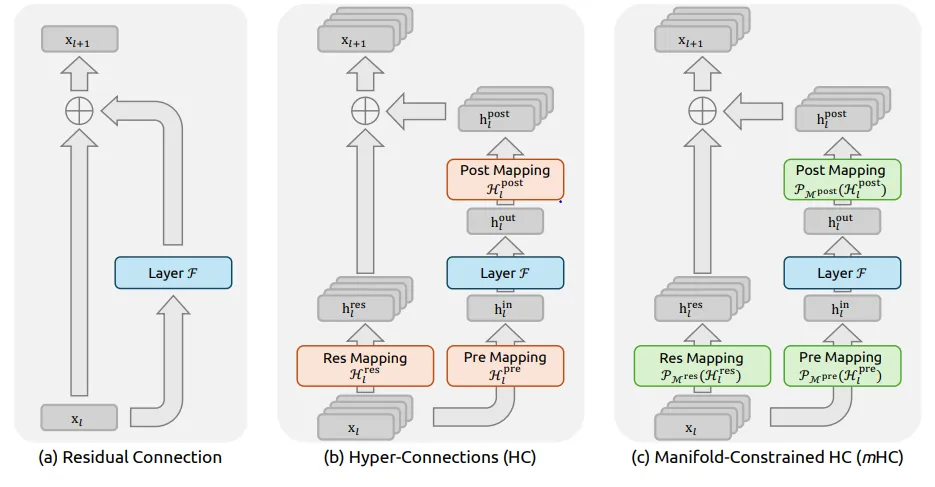
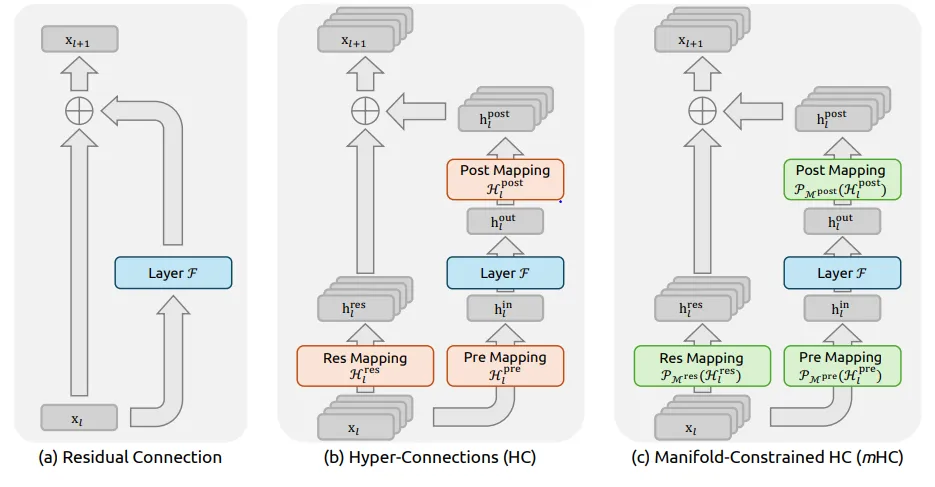
限制
- 梯度消失/梯度爆炸
- system overload
章节任务:获得高效稳定的HC网络
任务:模型训练稳定
调查HC网络结构
|
|
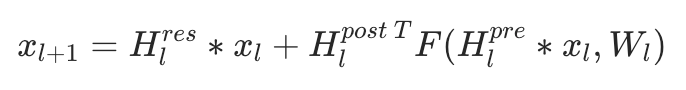
跳过Hres连接

—— 学习效果差
不跳过Hres连接
—— 梯度爆炸
调查Hres数值约束
- 所有元素都是非负的(大于或等于0)
- 每一行的所有元素之和等于 1
- 每一列的所有元素之和也等于 1
🌟 HA + 数值约束 = mHA!
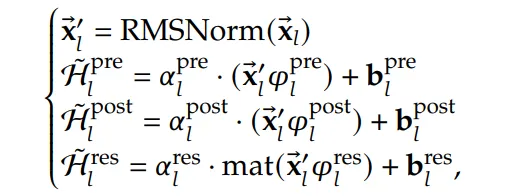
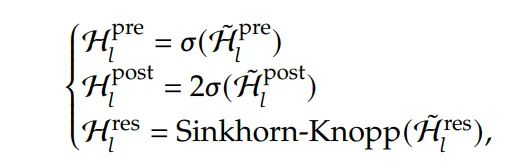
任务:将模型放到大规模集群下运行
调查mHA参数计算
按公式计算
RMSNorm 耗时过长
HA设计天然带有更多参数
RMSNorm 耗时过长
HA设计天然带有更多参数
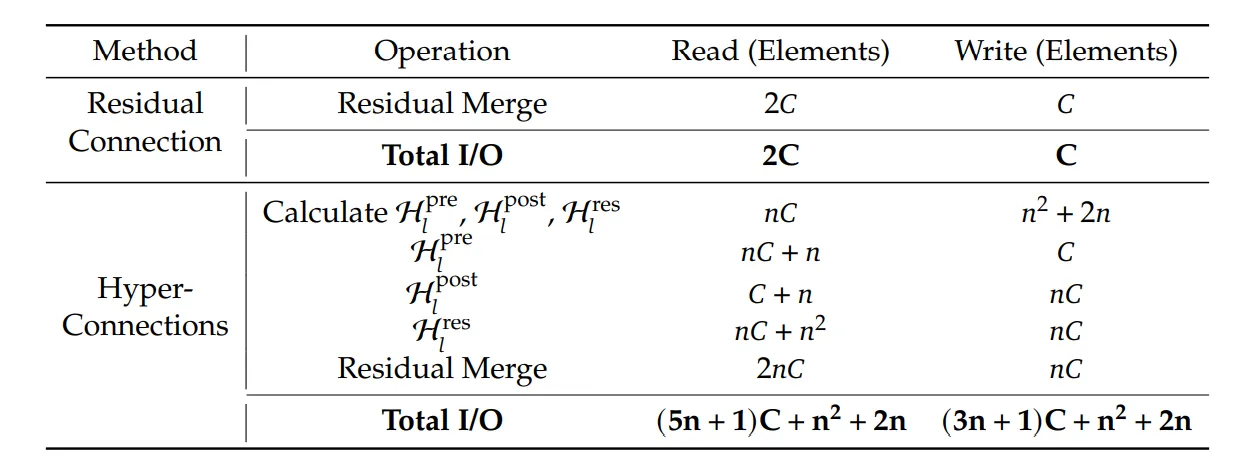
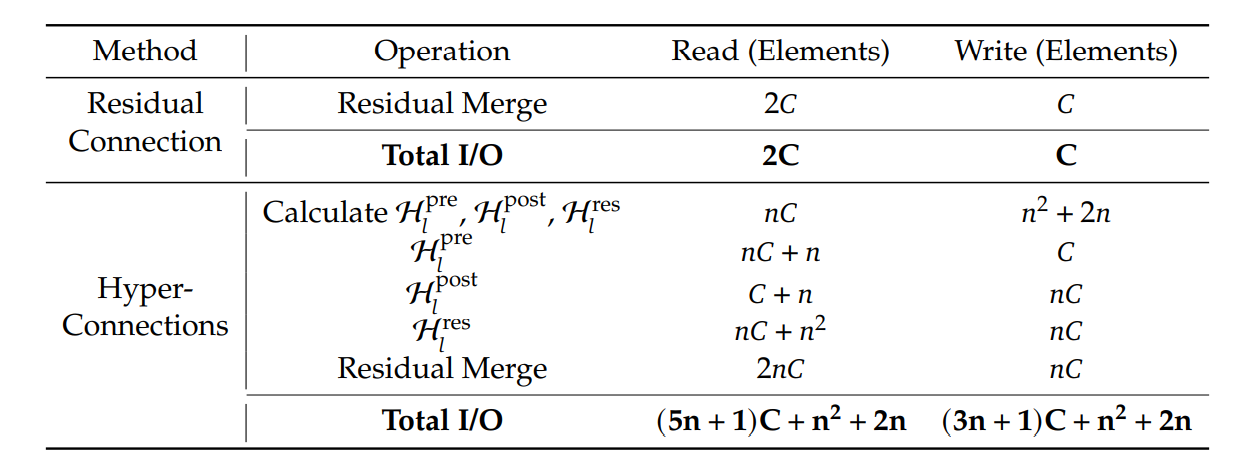
算子融合

被融合的原始独立算子 | 融合后形成的新内核 | 新内核实现的主要功能 |
1. Sinkhorn投影中的行/列归一化算子 | Sinkhorn迭代融合内核 | 在一个内核中,连续、原地完成矩阵的行求和与缩放、列求和与缩放,避免中间矩阵反复读写全局显存。 |
2. 投影矩阵 的存储算子 算子 | 投影-乘法垂直融合内核 | 在完成一个矩阵块的Sinkhorn投影后,立即将其与输入 的对应块进行计算,投影结果 不写回显存,实现“计算即消费”,彻底消除中间矩阵的I/O。 |
4. FP16/FP32类型转换算子 | 混合精度计算融合内核 | 在数据加载、计算核心、结果写回的不同阶段,无缝嵌入精度转换。例如,从显存以FP16加载,在芯片上转为FP32进行高精度Sinkhorn计算,最终结果转为FP16写回。 |
5. 激活函数算子 | 后处理融合内核 | 将矩阵乘法的输出,直接进行激活函数变换和RMSNorm的统计量计算与缩放,避免存储未归一化的中间激活值。 |
🌟 获得融合算子 !
调查需要缓存的参数
参数类别 | 具体参数 | 是否缓存 | 原因与说明 |
核心模型参数 | 投影前原始矩阵 | 是 ✅ | 重计算的“种子”。Sinkhorn投影的前向和反向计算都依赖于此。缓存它比缓存整个投影过程的所有中间值更节省显存。 |
| 层权重 (如FFN) | 是 ✅ | 重算层变换 所必需的可学习参数。 |
| RMSNorm 缩放参数 | 是 ✅ | 数据量极小(一个向量),为精确重算归一化步骤所必需。 |
关键激活检查点 | 网络主干输入 (在关键层) | 是 ✅ | 应用标准检查点技术,间隔性缓存某层的完整输入,作为重算一个网络片段的起点。 |
中间激活与派生数据 | Sinkhorn投影的所有中间矩阵 | 否 ❌ | 主要丢弃对象。数据量巨大,但可由原始 确定性地完全重算。 |
| 层内计算中间激活 (如FFN内部) | 否 ❌ | 数据量大,可由缓存的 和 重算。 |
| 投影后矩阵 | 否 ❌ | 虽然用于前向计算,但它是 的派生数据,可从 重投影得到。 |
🌟 获得重计算工作流!
调查Cuda调度原理
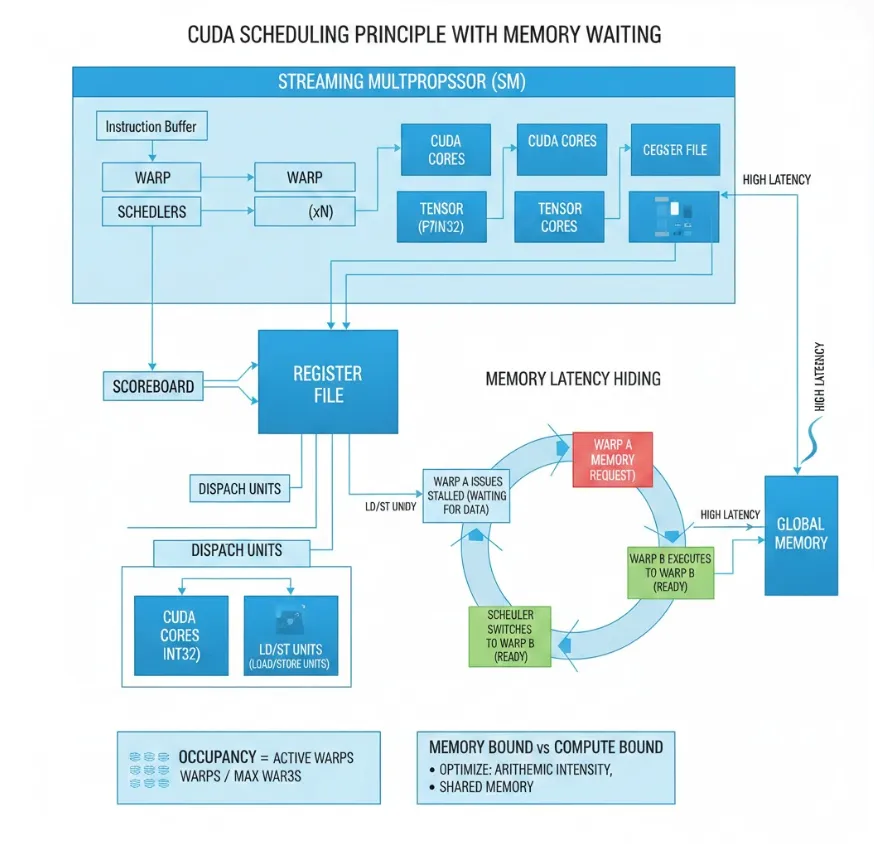
调查工作流
- 对旁路部分算子,使用高优先级cuda队列计算
- 重计算部分不占用IO等待

👑 Mission Complete!
