
C16 自指和自复制
前奏:一位烟民富于启发性的思想
前半部分:链接: https://pan.baidu.com/s/1I8lZDofQwmkqAXOEsxNkkQ?pwd=c2gm
提取码: c2gm后半部分:GEB第十六章 自指与自复制 录屏链接: https://pan.baidu.com/s/19OaJfu7PJVoCUunWPR5aMA?pwd=cyyr
密码: cyyr
本章与上下篇章的关系:
本书的基础:哥德尔的不完备定理。
人工智能-智能-人可以跳出系统?机器不能 - 人、意识、生命的溯源是有个核,那么猜想AI内在追溯到底也有个核(类似剥洋葱?)
简单的初始情况/信息,原材料制作方法,启动后可以组成复杂系统。
按照前言里的表述,故事与正文是一种对位(可以理解为意义的同构),新概念先以隐喻的形式出现在对话里,再在正文里讲解。而书本身是线型结构的,即章节与章节之间是某种顺承递进关系,所以十五章(及章前故事)是十六章(及章前故事)的启发是没错的。而抽烟者小故事里提及的核糖体与自噬,应当是和十六章里的核糖体,自复制对位。而十五章中并未提及核糖体等生物学概念。而生日歌小故事里不断要求阿基里斯就"今天是我的生日"给出证明,继而证明这证明…无穷尽也,明显对位着十五章里无穷性和不可证性。
——Yuan
阿基和螃蟹的对话:




它装不下。没有⼀个TNT 符号串能含有其⾃⾝哥德尔数的TNT 数字,因为这⼀数字总⽐该符号串本⾝含有更
多的符号。不过,你可以让G 含有其⾃⾝哥德尔数的⼀个描述,再利⽤“代⼊”和“算术㧟摁化”来绕过去。

(白南准)
隐性和显性的自指句子
(1) 本句⼦有七个字。
(2) 本句⼦⽆意义,因为它是⾃指的。
(3) 本句⼦⽆动词。
(4) 本句⼦是假的。(说谎者悖论)
(5) 正在写的这句话就是你正在读的那句话。
自指:
自复制:
这好像很简单,但是却要依赖于我们那种⾮常复杂而⼜完全内化了的驾驭语⾔的能⼒。这⾥,尤其重要的⼀件事是领会⼀个带有指⽰代词的名词性词组的所指。

(本句子是假的。)
为了辨认⼀个句⼦的⾃指性所需要的处理的相对⽐例,就像是图84 中的冰⼭的可⻅和不可⻅部分的相对⽐例。(通过表观去判断内在含义??)
图83 是⼀幅能在两个层次上解释的画。在⼀个层次上,它是⼀个指着⾃⼰的句⼦;在另⼀个层次上,它是说谎者处决⾃⼰的写照。
讨论(没读懂):基于同样的理由,哥德尔的符号串G 不能含有其哥德尔数的数字形式:它装不下。没有⼀个TNT 符号串能含有其⾃⾝哥德尔数的TNT 数字,因为这⼀数字总⽐该符号串本⾝含有更多的符号。不过,你可以让G 含有其⾃⾝哥德尔数的⼀个描述,再利⽤“代⼊”和“算术㧟摁化”来绕过去。
蒯恩的⽅法是使⽤描述——而不是⾃引⽤或词组“本句⼦”——来在⼀个句⼦中实现⾃指的⽅法之⼀,
蒯恩的构造在下述意义上极像哥德尔的构造:它通过描述另外⼀个(已经证明)同构于蒯恩句⼦的字符串来创造⾃指。对这串新字符的描述,是由这蒯恩句⼦的两个部分实现的。⼀部分是⼀组指令,它告诉我们如何建⽴⼀个词组,而另⼀部分则含有所要的素材,也就是说,这另⼀部分是⼀块模板。这也像冰⼭,但更像⼀块漂在⽔⾯上的肥皂(⻅图85)。

这个句⼦的⾃指性是靠⼀种⽐说谎者悖论更为直接的⽅法达到的,⽤不着多少隐蔽的处理。
一个自复制的程序
“㧟摁化”概念以及它在制造⾃指过程中的⽤处,对话中已经解释了,所以这⾥⽤不着再细讲。我们还是来
说明⼀下计算机程序如何能利⽤完全相同的技巧复制它⾃⼰。
DEFINE PROCEDURE “ENIUQ” [TEMPLATE]: PRINT [TEMPLATE, LEFT-BRACKET, QUOTE-MARK, TEMPLATE,
QUOTE-MARK, RIGHT-BRACKET, PERIOD].
定义过程“摁㧟”[模板]:打印[模板,左括号,单引号,模板,单引号,右括号,句号]。
ENIUQ
[‘DEFINE PROCEDURE ‘ENIUQ’ [TEMPLATE]: PRINT [TEMPLATE, LEFT-BRACKET, QUOTE-MARK,
TEMPLATE, QUOTE-MARK, RIGHT-BRACKET, PERIOD]. ENIUQ’].
摁㧟
‘[ 定义过程“摁㧟”[模板]:打印 [模板,左括号,单引号,模板,单引号,右括号,句号]。摁㧟’]。
“ENIUQ”是程序的前三⾏定义的⼀个过程,它的输⼊称作“TEMPLATE”[模板]。这个过程的意思是:调⽤这个过程时,TEMPLATE 的值是某⼀串印刷字符,ENIUQ 的结果是执⾏⼀项打印操作,其中要把TEMPLATE 打印两次:第⼀次只打印它,第⼆次在外⾯加上引号和括号,最后还要缀上⼀个句号。这样,如果TEMPLATE 的值是符号DOUBLE-BUBBLE(意为“两个泡泡”),执⾏ENIUQ,就得到
DOUBLE-BUBBLE[‘DOUBLE-BUBBLE’]。
类似编程语句的感觉?
【指令】和【程序】
在这个程序中,有⼀个符号串以两种⽅式起着作⽤,⾸先是作为程序,其次是作为数据。这就是⾃复制程序的秘密。而且,如我们将要看到的,这也是⾃复制分⼦的秘密。
(与乌龟对蒯恩型说谎者⾃指句⼦类似)
自复制:
- 规定按照一个指定程序执行复制
- 复印机(但是忽视了复印机内在的处理机器)----机器不一定是自愿复制的,它是被使用者被迫进行复制的,能是真正的自复制吗?
什么是副本
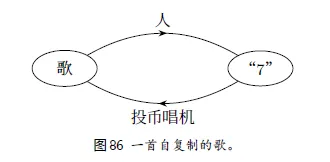
1、一首自复制的歌
投币-按钮7-唱歌 -------------是自复制吗? 不一定,因为7是一个触发器,不是一个副本。
2、一个“螃蟹”程序是不是自复制?(正反推论)
BlooP 的语⾔写⼀个程序
我们可以说这个输出与这个程序的“内在消息”相同,不过却有不同的“外在消息”——也就是说,必须⽤不同的解码⽅式来读它们。现在,如果把外在消息看成信息的⼀部分——这好像⼗分合理——那么,全部的信息终归并不相同。所以这个程序不能算是⾃复制。
???
“固有意义”,其思想是,在确定⼀个对象的固有意义时,我们可以忽视某些类型的外在消息——那些能够普遍被理解的信息。也就是说,在某种仍有缺陷的意义上,如果解码机制看上去⾜够基本,那么所要揭⽰的内在消息就是该考虑的唯⼀意义。在这个例⼦中,就似乎有充分的把握猜想⼀个“标准智能”会认为两个镜像含有彼此相同的信息。这也就是说,它认为两者之间的同构映射⼗分不⾜道,以⾄可以忽略。因而,我们可以认为在某种意义上,该程序算是个⼗⾜的⾃复制。这样的直观是站得住脚的。
3、说谎者横跨太平洋
打印自己的程序
你可能要试着写写这个怪诞的混和物所描述的句⼦(提⽰:它不是它⾃⼰——或者说,⾄少当“它⾃⼰”取朴素的意义时,它不是它⾃⼰)。如果“逆⾏⾃复制”(即倒着写出⾃⾝的程序)的概念让⼈想起螃蟹卡农,那么“翻译的⾃复制”概念⼤概会使⼈想起带有主题转调的卡农。
4、打印自己的哥德尔数的程序
5、哥德尔式自指
6、通过增值达到的自复制(引到后面)
⽣物的⾃复制过程。显然任何⼀个⽣物体都不全同于⽗⺟,那为什么⽣⼉育⼥这⼀类事情还叫“⾃复制过程”呢?答案是,双亲和孩⼦之间有⼀个粗略的同构。这是⼀个保持物种信息的同构。因此,复制的东西是类而不是例。
7、凯姆式自复制
什么是原件?
(1) ⼀个程序,如果⽤⼀个在计算机上运⾏的解释程序来解释它,它就把⾃⼰打印出来;
(2) ⼀个程序,如果⽤⼀个在计算机上运⾏的解释程序来解释它,它就把⾃⼰连同该解释程序的⼀个完整副本(毕竟也是个程序)⼀起打印出来;
(3) ⼀个程序,如果⽤⼀个在计算机上运⾏的解释程序来解释它,它就不仅把它⾃⼰连同该解释程序的⼀个完整副本都打印出来,而且还指挥着⼀个机械的装配过程,⼜装配起⼀部计算机,与那台运⾏着该程序及那个解释程序的计算机⼀模⼀样。
很明显,在(1) 中,该程序是个⾃复制。而在(3) 中,它究竟是个⾃复制程序,还是程序加上解释程序的混合系统,还是程序、解释程序以及处理机的联合体呢?
本章余下的⼤部分篇幅都将⽤来讨论那些把数据、程序、解释程序、处理机全搅在⼀起的⾃复制。
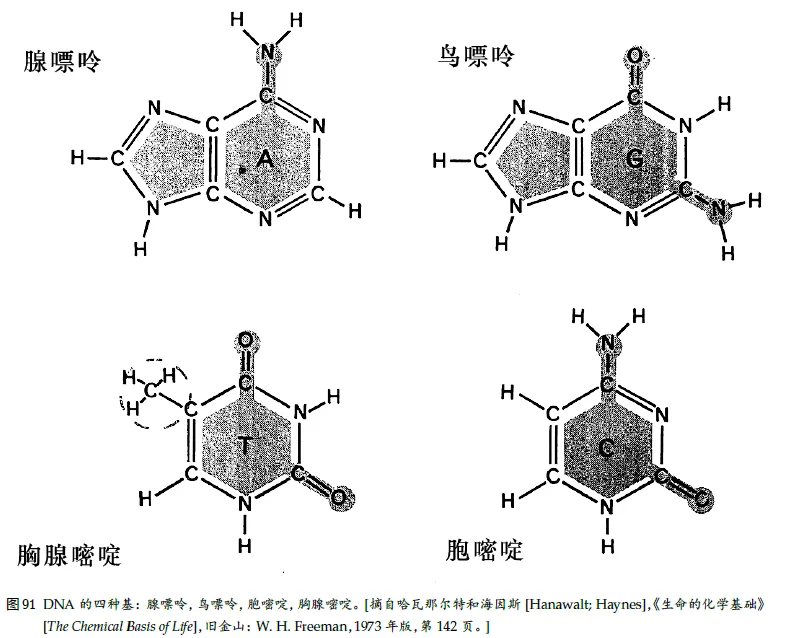
1、印符遗传学
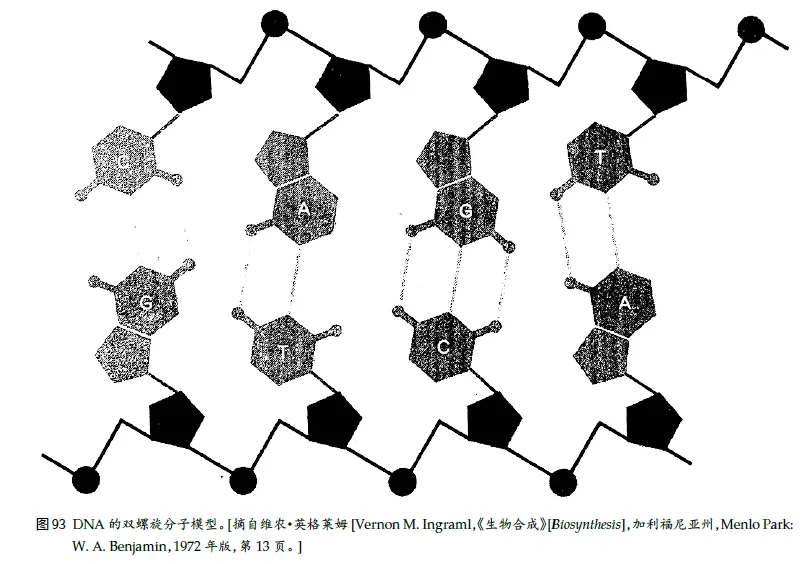
弗兰西斯·克⾥克(DNA 双螺旋结构的发现者之⼀)所阐述的、集中在著名的“分⼦⽣物学中⼼法则”⾥的那些过程:
DNA ⇒ RNA ⇒ 蛋⽩质
2、串、基、酶
3、复制状态和双串
AC TG碱基互补配对原则
DNA知识:https://www.youtube.com/watch?v=Z9ljn1apgEI
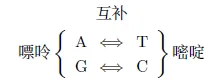
DNA复制过程:https://www.bilibili.com/video/BV1sA411x7Zc
“复制”⼀个串时,并不是实际复制它,而是产⽣出它的补串,并把它倒过来写在原串的上⽅。我们来具体看看,让上述的酶作⽤在下⾯的串上(这个酶恰好也喜欢从A 出发):
CAAAGAGAATCCTCTTTGAT
步骤1:寻找右边最近的嘧啶。
步骤2:复制状态,好,把A 倒过来放在我们的T 上⾯。不过这并没有完,复制状态会继续保持有效,直到从其中退出——或者直到酶做完为⽌。这意味着复制过程继续进⾏,于是酶所通过的每⼀个基上⾯都放上了⼀个补基。
步骤3:是说找到我们的T 右边的⼀个嘌呤。
步骤4:切断这个串,得到两段。

4、氨基酸
cut —— 切断串
del —— 从串⾥删除⼀个基
swi —— 把酶转移到另⼀个串上
mvr —— 右移⼀个单元
mvl —— 左移⼀个单元
cop —— 进⼊复制状态
off —— 退出复制状态
ina —— 在本单元右侧插⼊A
inc —— 在本单元右侧插⼊C
ing —— 在本单元右侧插⼊G
int —— 在本单元右侧插⼊T
rpy —— 寻找右边最近的嘧啶
rpu —— 寻找右边最近的嘌呤
lpy —— 寻找左边最近的嘧碇
lpu —— 寻找左边最近的嘌呤
举例子:我们随便写⼀个酶:
rpu-inc-cop-mvr-mvl-swi-lpu-int
和⼀个任意的串:
TAGATCCAGTCCATCGA
碰巧,这个酶只拴在G 上,我们就把它拴在中间的G 上,并开始⼯作,向右寻找⼀个嘧啶(即A 或G)。我们(即酶)跳过TCC,然后停在A 上。插⼊⼀个C,于是有
TAGATCCAGTCCACTCGA
↑
其中的箭头指着酶所拴的单元。进⼊复制状态。于是在C 上放⼀个倒置的G。右移,再左移,然后转移到另⼀个串上。迄今为⽌我们已有

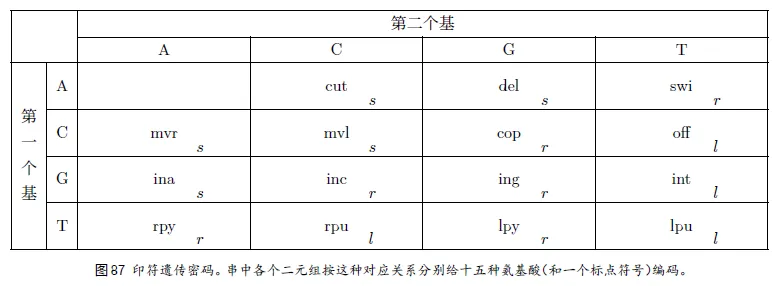
5、翻译和印符遗传密码
“⼆元组”——表⽰各种不同的氨基酸。总共有⼗六种可能的⼆元组:AA、AC、AG、AT、CA、CC、等等,而氨基酸共有⼗五种。印符遗传密码如图87 所⽰。
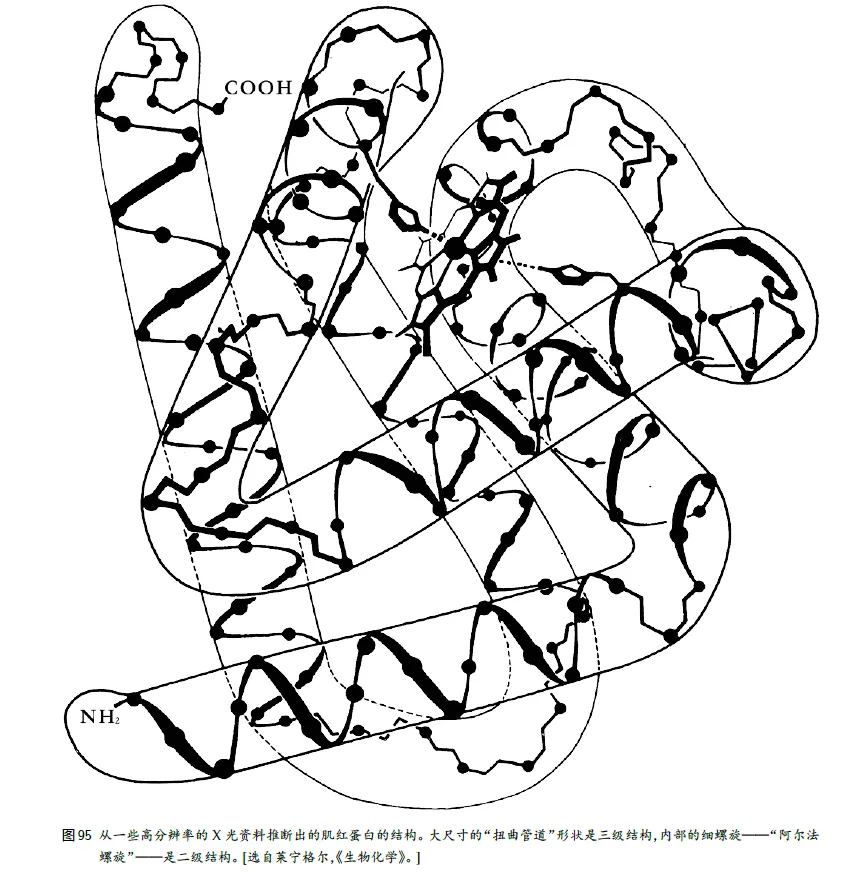
6、酶的三级结构
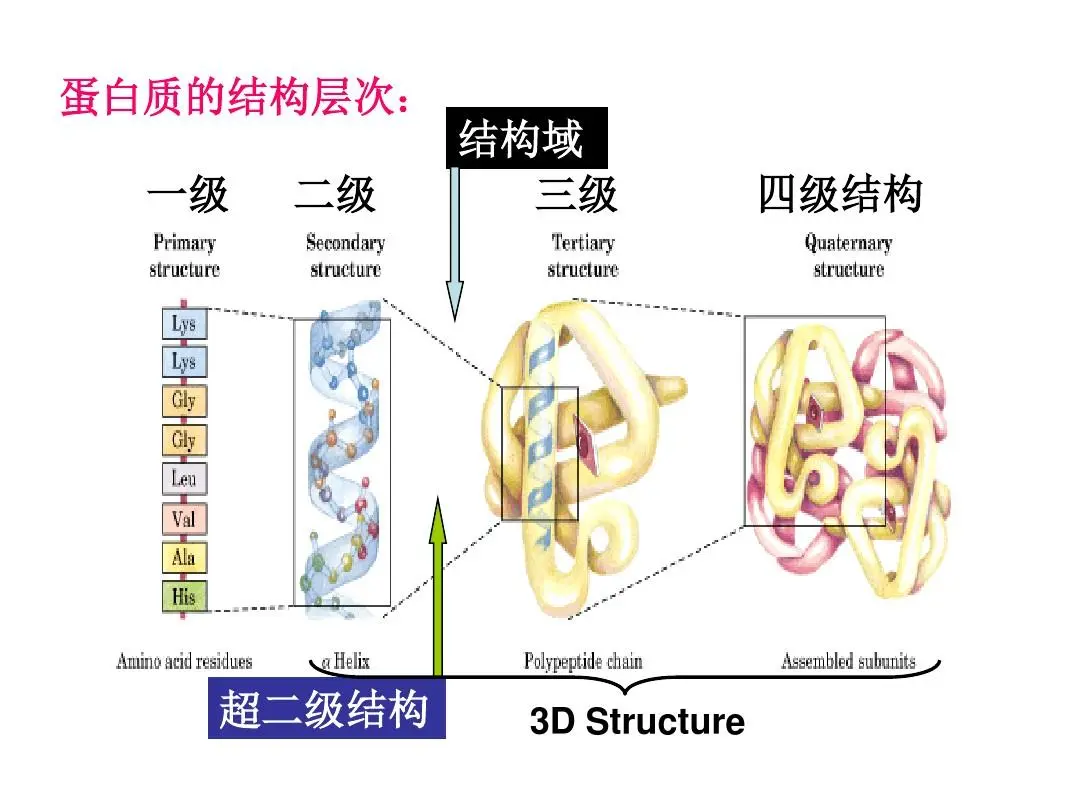
蛋白质的⼀级结构:氨基酸序列,
二级结构:多肽主链骨架原子沿一定的轴盘旋或折叠而形成的特定的构象,即肽链主链骨架原子的空间位置排布,不涉及氨基酸残基侧链。蛋白质二级结构的主要形式包括α-螺旋、β-折叠、β-转角和无规卷曲。
三级结构:它喜欢的“折叠”⽅式,通过疏水键、盐键、二硫键、氢键等相连。
四级结构:指亚基与亚基之间呈特定的三维空间排布,并以非共价键相连接。
7、印符遗传学的中心法则
8、信使RNA与核糖体(下一次)
#mRNA,tRNA,rRNA: https://www.youtube.com/watch?v=1THyMOk3WU0(感兴趣可以看)
核糖体:https://www.youtube.com/watch?v=LbLOhLupgiU
mRNA ——信使RNA——"邮政快递"
它把储存在细胞核内的DNA 中的信息或命令,传递给细胞质中的核糖体。
方法:细胞核内部⼀种特殊类型的酶把DNA 基序列中的⼀个个⻓段忠实地复制到⼀个新串——信使RNA 串——上。然后,这个mRNA 就离开细胞核,漫步走⼊细胞质,在那⾥它⼜跑进很多核糖体内,这些核糖体就开始根据它来制造酶。
在细胞核内把DNA 复制到mRNA 上的过程叫转录。
“RNA”表⽰“核糖核酸”,AUCG
9、氨基酸
蛋⽩质由⼀系列氨基酸组成。氨基酸共有⼆⼗个品种,每⼀种都由三个字⺟来表⽰:
ala —— 丙氨酸arg —— 精氨酸
asn —— 天⻔冬氨酰胺asp —— 天⻔冬氨酸
cys —— 胱氨酸gln —— ⾕酰胺
glu —— ⾕氨酸gly —— ⽢氨酸
his —— 组氨酸ile —— 异⽩氨酸
leu —— ⽩氨酸lys —— 赖氨酸
mef —— 蛋氨酸phe —— 苯基丙氨酸
pro —— 脯氨酸ser —— 丝氨酸
thr —— 苏氨酸trp —— ⾊氨酸
tyr —— 酪氨酸val —— 缬氨酸
必需氨基酸:人体自身不能合成或合成速度不能满足人体需要,必须从食物中摄取的氨基酸。
一家人来写两三本书。一(异亮氨酸IIe),家(甲硫氨酸Met),来(赖氨酸Lys),写(缬氨酸Val),两(亮氨酸Leu),三(色氨酸Trp),本(苯丙氨酸Phe),书(苏氨酸Thr)。
其中,甲硫氨酸Met又叫蛋氨酸。
1、合成组织蛋白。
2、变成酸、肌酸、激素、抗体等含氨物质。
3、转变为碳水化合物与脂肪。
4、氧化成二氧化碳、水及尿素,并且产生能量。
10、核糖体和录音机
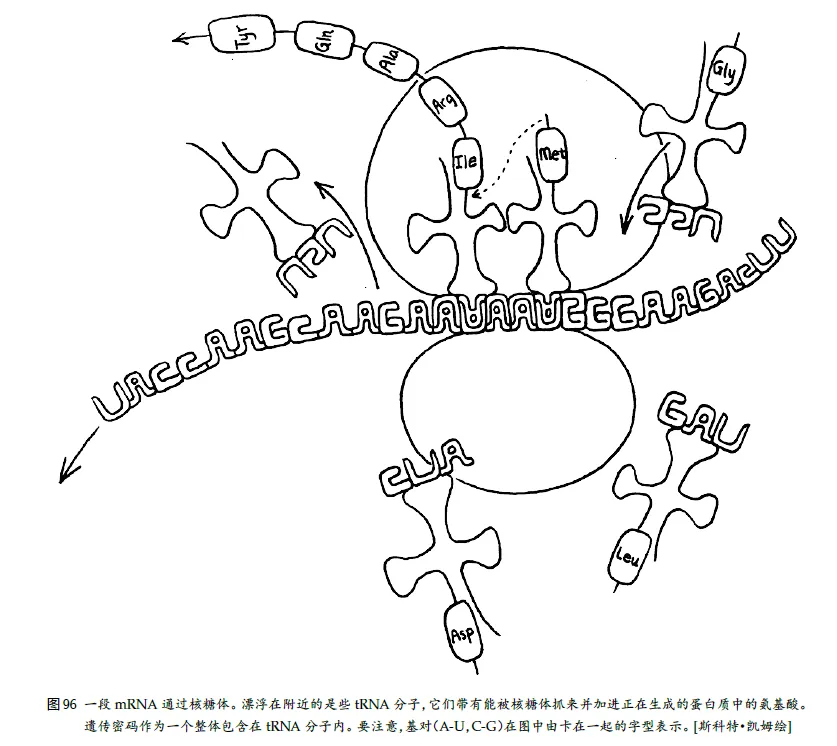
当⼀个mRNA 串游离出来进⼊细胞质,然后遇到⼀个核糖体时,会发⽣⼀个极其复杂而⼜精彩的过程,我
们称之为翻译。
过程:把mRNA 设想成⼀⻓条录⾳磁带,而核糖体就像⼀台录⾳机。当磁带通过录⾳机的放⾳磁头时,信号就被“读出”并转变成⾳乐或其它声响。就这样,磁记号“翻译”成了⾳符。与此类似,当mRNA“磁带”通过核糖体的“放⾳磁头”时,产⽣出的⾳符是氨基酸,而作出的“乐曲”是蛋⽩质。所谓翻译也就是这些。
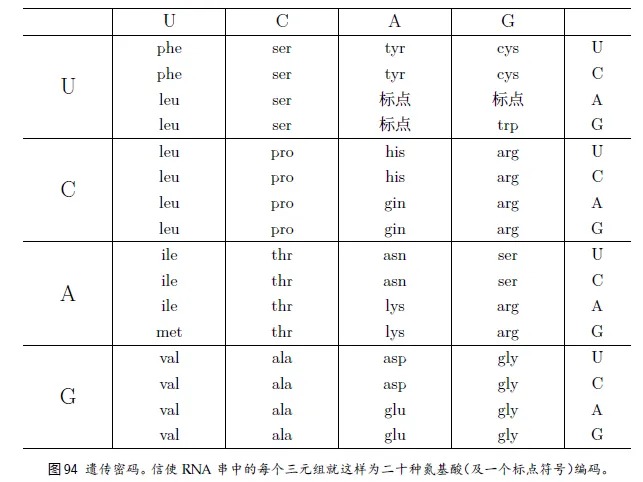
11、遗传密码
12、三级结构(见前)
13、蛋白质功能的简化论解释
在印符遗传学中,组成酶的每个氨基酸都负责某个具体的“作⽤⽚断”;而在实际的酶中,单个的氨基酸不能充当这种明确的⻆⾊。确定酶的作⽤⽅式的,是作为⼀个整体的三级结构。
酶的功能不能看成是由各个部分的上下⽂⽆关的功能建⽴起来的,而必须考虑各部分之间的相互作⽤。
具体情况,具体分析。
14、转移RNA与核糖体
细胞质周围都四散漂浮着⼤量的四叶草形分⼦,在它们的⼀个叶⽚上,松松地拴着(即靠氢键相连)⼀个氨基酸,而在对⾯的叶⽚上有⼀个称为反密码⼦的核苷酸三元组。
当⼀个新的mRNA 密码⼦进⼊核糖体的“放⾳磁头”的位置时,核糖体就伸⼿到细胞质中抓住⼀⽚其反密码⼦恰与该mRNA 密码⼦互补的草,然后把这⽚草拽到这样⼀个位置上:能揭下叶⼦上的氨基酸,⽤⼀个共价键把它粘到正在⽣成的蛋⽩质上(顺便说⼀句,⼀个氨基酸在蛋⽩质中与其邻居之间的键是⼀种很强的共价键,称为“肽键”。因此,蛋⽩质有时也叫“多肽”)。当然,“草”上带有合适的氨基酸并不是偶然的,因为它们全是根据来⾃“⾦銮殿”的严格指令⽣产出来的。这种草的真正名字叫转移RNA(tRNA)。
15、标点和阅读框架
和印符遗传学⼀样,mRNA 中也有⼀个记号,指⽰出⼀个蛋⽩质的结束或开始。事实上,有三个特殊的密码⼦——UAA、UAG、UGA——都起标点符号的作⽤,
当这样的⼀个三元组⼀下⼀下地滑⼊核糖体的“放⾳磁头”时,核糖体就放走正在构造的那
个蛋⽩质,然后开始构造⼀个新的蛋⽩质。
DNA转录翻译:https://www.youtube.com/watch?v=sACba5mrbtY
转录和翻译专业版:https://www.youtube.com/watch?v=bKIpDtJdK8Q
16、蛋白质和音乐中的多层结构和意义
我们已经把核糖体的形象⽐作录⾳机,mRNA ⽐作磁带,而蛋⽩质则是⾳乐。
比喻:
⼀级结构、⼆级结构、三级结构和四级结构,这四个层次还可以⽐作《前奏曲,蚂蚁赋格》中的“⽆之图”(图60)的四个层次。总的结构——由两横⼀撇及⼀个竖弯钩组成⼀个“⽆”字——是它的四级结构;那两横及那⼀撇⼀竖弯钩本⾝是三级结构,分别由“整体论”和“简化论”组成;而三级结构的“整体论”与“简化论”其笔划分别由⼆级结构的“简化论”和“整体论”组成,最后,⼀级结构则是⼀遍⼜⼀遍地重复“⽆”字。

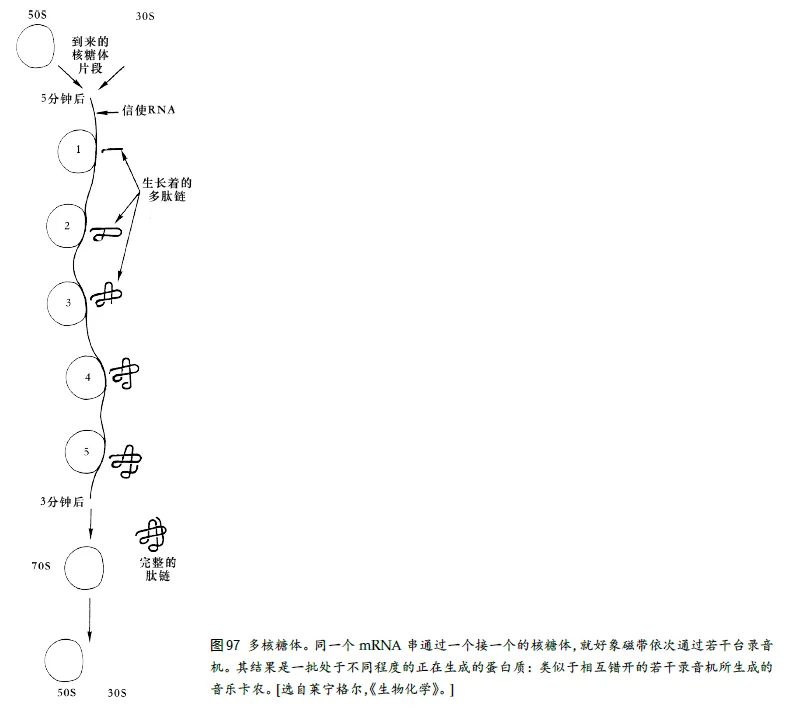
17、多核糖体和二排卡农
我们再来看看把磁带翻译成⾳乐的录⾳机,与把mRNA 翻译成蛋⽩质的核糖体两者之间的另⼀个优美的平⾏关系。设想有许多磁带录⾳机⼀字排开,间隔相等。我们可以把这个阵势叫做“多录⾳机”。再设想同⼀条磁带陆续通过各个录⾳机的放⾳磁头,如果磁带上录有⼀个完整的⻓旋律,那么输出⾃然是⼀个多部轮唱,各声部之间的延迟由磁带从⼀台录⾳机起到下⼀台录⾳机所⽤的时间来确定。
在细胞中,确实也存在这种“分⼦卡农”,那⾥,很多核糖体⼀字排开,形成所谓多核糖体。它们全都“使⽤”同⼀个mRNA 串,错开⼀定时间,⽣产同样的蛋⽩质(⻅图97)。
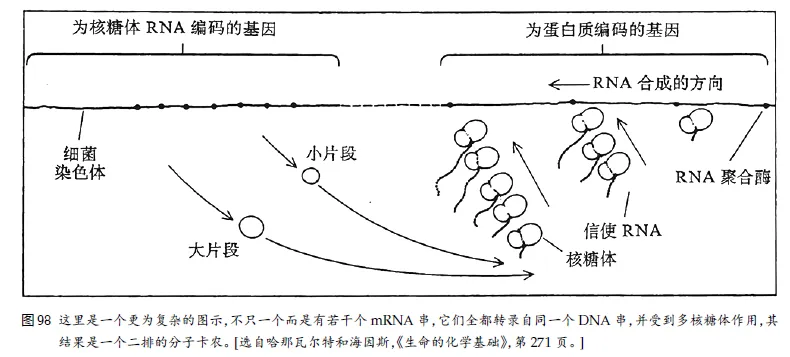
18、谁生谁——核糖体和蛋白质
核糖体由两种东西构成:(1) 各类蛋⽩质,(2) 另⼀种RNA,叫做核糖体RNA(rRNA)。
为了造出核糖体,得有某些种类的蛋⽩质,还得有rRNA。⾃然,要有蛋⽩质就得有核糖体来制造它。
先有谁——核糖体还是蛋⽩质?谁制造谁?当然不会有答案,因为往前追溯总是会遇到当前对象的同类——就像先有鸡还是先有蛋的问题⼀样——直到⼀切都消失在时间的地平线上为⽌。
19、蛋白质的功能
酶——高效的催化剂,也是一种蛋白质。
它怎样在细胞⾥的分⼦上起作⽤呢?如已经讲过的那样,酶是折起的多肽链,每个酶中都有⼀个裂缝或口袋或某种别的清晰定义的外观特性,酶在那⾥拴住某个其它种类的分⼦。这个地点叫活性部位,拴在那⾥的分⼦叫基质。酶可以有不⽌⼀个活性部位和不只⼀个基质。
⼀旦把酶与其基质拴在⼀起,就会发⽣某种电荷不平衡状态,随后,电荷——以电⼦或质⼦的形式——就围绕着拴住的分⼦流动并重新排布⾃⼰。达到平衡时,基质可能已经发⽣了意义深刻的化学变化。
印符酶和⽣物酶之间还有⼀个显著的区别,那就是:印符酶只作⽤在串上,而⽣物酶则可以作⽤在DNA、RNA、其它蛋⽩质、核糖体以及细胞膜之上——简⾔之,作⽤于细胞⾥的每⼀样东西。换句话说,酶是在细胞内
使各种事件得以发⽣的通⽤机器。有各种各样的酶,有的能把东西粘在⼀起,有的⼜把它们分开,有的修改它们,
有的激活它们,有的安定它们,有的复制它们,有的恢复它们,有的毁坏它们……
20、需要有⼀个⾜够强有⼒的⽀撑系统
“什么样的DNA 串能指挥⾃⼰的复制?”?并⾮每个DNA 串⽣来都是⾃复制。
关键在于:任何⼀个想要指挥⾃⼰的复制⼯作的串,都必须含有⼀些命令,以便能恰好调集那些能够执⾏这⼀任务的酶。
期间需要有核糖体,RNA 催化酶等物质的支持,所以我们必须从假定有⼀种刚好强到允许转录过程和翻译过程得以进⾏的“极小⽀撑系统”开始。
21、DNA自复制与层次意义
“⾜够强有⼒的⽀撑系统”和“⾜够强有⼒的形式系统”,⼀个是产⽣⾃复制的前提,⼀个是产⽣⾃指的前提。
DNA 必定含有⼀组蛋⽩质的密码,而这组蛋⽩质就将复制这个DNA。有⼀种⼗分有效而精致的办法能复制⼀个由互补的两个串组成的双串DNA。这包括两步:
(1) 把两个串彼此分开,
(2) 给刚刚得到的两个新的单串各“配”上⼀个新串。
在细胞内这两个步骤是通过⼀种协调的⽅式⼀起进⾏的,而且需要三种主要的酶:DNA 核酸内切酶,DNA 催化酶和DNA 连接酶。
- 第⼀种是个“拉开酶”:它把原有的两个串剥开⼀小段距离,然后停⽌。
- 催化酶基本上是⼀种完成“复制并移动”操作的酶:它切下DNA 的⼀个短短的单串,以⼀种会使⼈联想起印符遗传学中的复制状态的⽅式⽤补基来复制它们。为了复制,它要利⽤在细胞质中四处漂浮的⼀些原料——尤其是核苷酸。由于这个过程是阵发性的,每次都剥开⼀些东西,复制⼀些东西,所以就产⽣了⼀些小缝隙,而DNA 连接酶就是堵缝的东西。
- 重复。这部精密的三酶机就以⼀种小⼼翼翼的⽅式⼀路沿着DNA 分⼦运⾏着,直到整个东西都被剥开,同时也被复制,最后有了两个副本为⽌。
从⼀个DNA 串⾥可以读出好⼏个不同层次的意义:
在最低的层次上,每⼀个DNA 串给⼀个等效的RNA 串编码——作为转录的编码过程。
如果将DNA组块而形成三元组,那么,利⽤“遗传解码器”就能把DNA 读成⼀系列氨基酸。这是(在转录之上的)⼀个翻译。
在下⼀个⾃然的层次上,DNA ⼜可读成⼀组蛋⽩质的代码。
最高层次:把蛋⽩质从基因⾥拽出来的物理过程叫做基因表⽰。 基因组

22、中心法则
1、中心法则映射
克⾥克的“分⼦⽣物学中⼼法则”(即DNA ⇒ RNA ⇒ 蛋⽩质)(称做法则I,这是⼀切细胞过程的基础)和
我富有诗意的发明——“数理逻辑中⼼法则”(称作法则II,是哥德尔定理的基础)——之间做⼀个精细的⽐较。
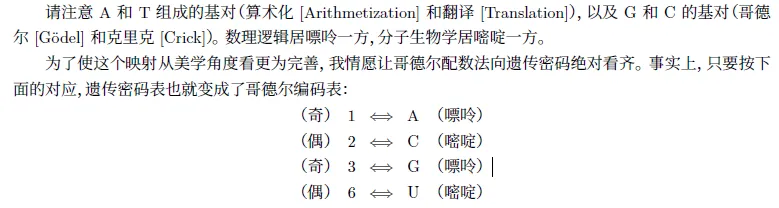

2、中心法则映射怪圈
左边,是作⽤在作⽤在蛋⽩质上的蛋⽩质上的蛋⽩质,等等,直⾄⽆穷;而右边,是关于关于元TNT 陈述的陈述
的陈述,等等,直⾄⽆穷。
这些都类似于我们在第五章中讨论过的异层结构,在那⾥,⼀个⾜够复杂的基质就可以使⾼层怪圈出现,并不断地兜圈⼦,以⾄完全隔离于较低的层次。我们将在第⼆⼗章中详细探究这⼀思想。
(没太理解下图)???
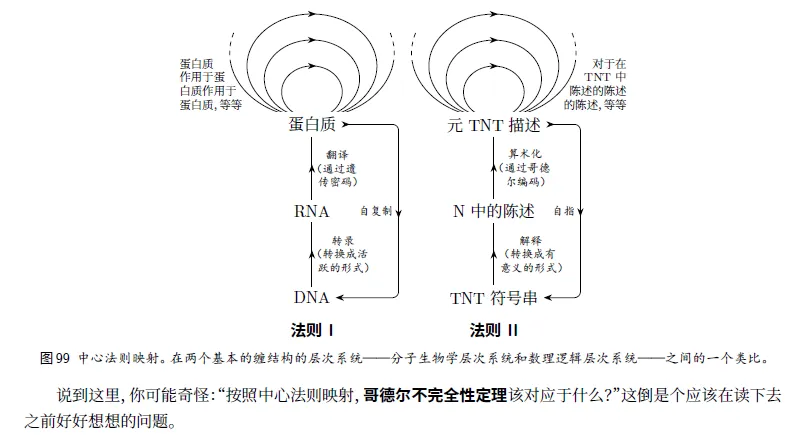
可以通过无限次自指递归的方法来创造比较复杂的系统。
3、中⼼法则映射与《对位藏头诗》
中⼼法则映射⼗分类似于第九章中建⽴的《对位藏头诗》与哥德尔定理之间的映射。因此,我们可以找出全部三个系统之间的平⾏性:
(1) 形式系统和符号串,
(2) 细胞和DNA 串,
(3) 唱机和唱⽚。

进化论。
分化不组装成形式系统可以避免被哥德尔定理分化。
23、⼤肠杆菌与T4 之战
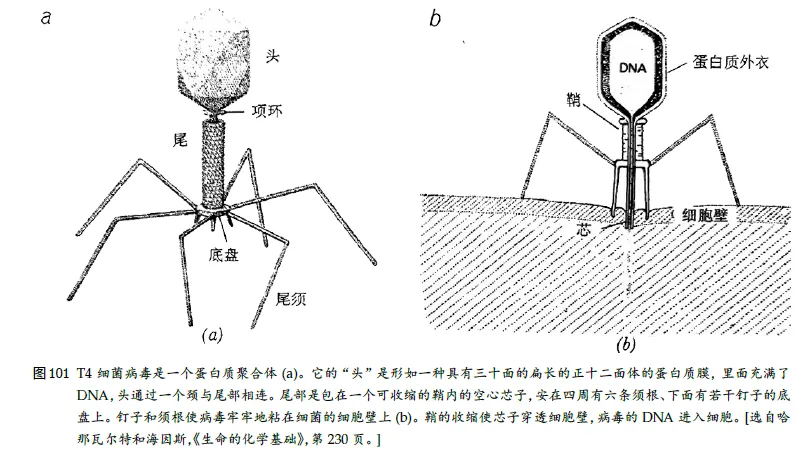
⼤肠杆菌细胞和⼊侵这种细胞的家伙:凶恶可怕的T4 噬菌体,这种神奇的小东西看上去有点像登⽉舱和蚊⼦的混⾎⼉,可它却⽐蚊⼦凶得多。它有⼀个“头”,⾥⾯储存着它的全部“知识”——即它的DNA;它有六条“腿”。
蚊⼦利⽤它的刺针来吸⾎,而T4 噬菌体则利⽤它的剌针违背它的牺牲品的意志,把⾃⼰的遗传物质强⾏注⼊细胞。
T4噬菌体被证明是一个解决基因和信息传递本质的理想体系,是生命科学研究的一种模式生物。
24、分子特洛伊木马
病毒进入细胞后类似特洛伊木马
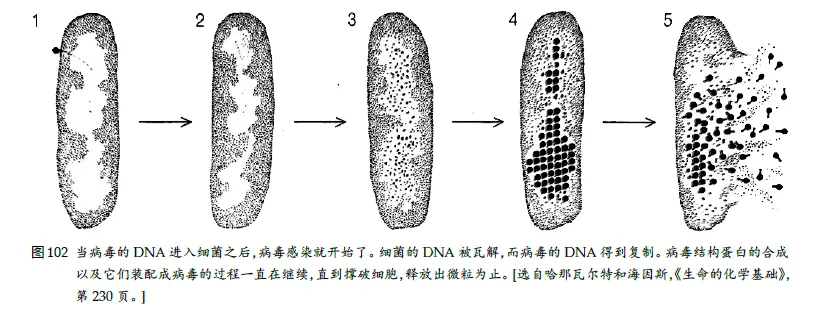
按拟⼈的说法,病毒“希望”它的DNA 能得到与宿主细胞的DNA完全相同的待遇。这就意味着要能被转录和被翻译,于是就使它可以指挥合成它⾃⼰的特殊的、与宿主细胞相异的蛋⽩质,然后这些蛋⽩质就开始各司其职。这相当于利⽤“密码”(即遗传密码)秘密地把外来蛋⽩质输送到宿主细胞中,然后再来“解码”(制造它们)
25、识别、伪装、标识
识别过程是细胞和亚细胞⽣物学的中⼼主题。分⼦(或⼀些⾼层结构)如何互相识别?为了做到这⼀点,酶必须能锁在其基质的特殊“拴缚部位”上,细菌必须能区别它⾃⼰的DNA 和噬菌体的DNA,两个细胞必须能通过⼀种有控制的⽅式彼此识别和相互作⽤。
这种识别问题类似:你怎么才能说清⼀个符号串有没有某种性质(⽐⽅说“是定理”)?有没有⼀个判定过程?
数理逻辑——计算机科学——分⼦⽣物学都相通。
其思想是:DNA 串能通过⼀种化学⼿段来标识,即把⼀个小分⼦——甲基——排在各种核苷酸上。这种标识操作并不改变DNA 的正常⽣物性质,换句话说,甲基化(标识了的)的DNA 能够转录得和未甲基化(未标识的)的DNA ⼀样,所以它仍然能指挥蛋⽩质的合成。但是,如果主体细胞有某些特殊机制能检验DNA 是否有标识,那么这种标识就会是⾮常重要的了。具体地说,主体细胞可能有⼀个酶系统来搜寻未加标识的DNA,而且只要找到这样的DNA 就毫不留情地把它砍碎破坏掉。
核苷酸上甲基标识可以⽐作⼀个书法流派的特征。利⽤这种⽐喻,我们可以说⼤肠杆菌细胞在寻找以其“本派字体”——即与它⾃⼰特征⼀致的书法——写下的DNA,并砍掉以“异端”书法写下的⼀切DNA。当然,噬菌体的反策略则是学会标识⾃⼰,从而哄骗那些它们打算侵⼊的细胞来复制⾃⼰。
???没看懂任何⼀种成功地获得这种⾃复制⽅法的病毒DNA,都可以说是具有这样⼀种⾼层次的解释:“我可以在X 型细胞内被复制。”⼀定要把这与早先谈到的、在进化论上没有什么意义的那种噬菌体区别开来。早先谈的那种噬菌体是给破坏⾃⼰的那些蛋⽩质编码,其⾼层解释则是⼀个⾃戕句⼦:“我不能在X 型细胞内被复制。”
26、汉肯句⼦与病毒 隐式汉肯句⼦之别于显式汉肯句⼦
我们讨论过⾃戕噬菌体的类⽐物——哥德尔型的符号串,它断⾔⾃⼰在特定的形式系统中不可制造。此外,我们还可做出⼀个与实际噬菌体相应的句⼦:该噬菌体断⾔了它⾃⼰在特定的细胞内可以⽣成。这样的句⼦就是断⾔它⾃⼰在特定形式系统中可以⽣成。这类句⼦被冠以数理逻辑学家列昂·汉肯的名字,称作汉肯句⼦。

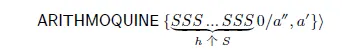
汉肯句子:0是二进制代码。------------00001100
???接后就能看懂汉肯句⼦这⼀主题的⼀个变奏——明确描述了⾃⼰的推导过程的句⼦。这种句⼦的⾼层解释就不是“存在某个符号串序列是我的推导”,而是“此处描述的符号串序列……是我的推导。”我们把前⼀种句型叫隐性汉肯句⼦,而把这种新型的句⼦称作显性汉肯句⼦,因为它们显式地描述了⾃⼰的推导。应当注意的是,显性汉肯句⼦与其隐性的弟兄们不同,它们不⼀定是定理。事实上,很容易写出⼀个符号串,它断⾔⾃⼰的推导由单个符号串0 = 0 组成,但这是个假句⼦,因为0 = 0 不是任何东西的推导。不过,也可以写出⼀个是定理的显性汉肯句⼦——即事实上给出它⾃⼰的推导⽅案的句⼦。
27、汉肯句⼦和⾃组装
有⼀类病毒(⽐如所谓的“烟草花叶病毒”),叫做⾃组装病毒;同时也还有另⼀类病毒,⽐如我们最喜欢⽤的T 偶数族病毒,叫做⾮⾃组装病毒。区别何在?这可以直接类⽐于隐性和显性的汉肯句⼦。
⼀个⾃组装病毒的DNA 只给新病毒的各个部分编了码,而不给任何酶编码。⼀旦这些部分都造了出来,那个诡秘的病毒就依靠它们⾃⾏连接起来,而⽏需什么酶的帮助。这样的过程依赖于各个部分在细胞的醇厚饮料中游泳时彼此之间所具有的化学亲和⼒。
反之,诸如T 偶数号那样的⽐较复杂的病毒的DNA,就不仅给各个部分编码,而且也给在各部分组装成整体的过程中起特殊作⽤的各种酶编码。由于这个组装过程不是⾃发的而是需要“⼀些装置”,所以这些病毒不能看作是⾃组装。
本质上讲就是:前者不必告诉细胞任何有关它们结构的事情,就安然完成⾃复制,而后者则需要给出⼀些有关如何组装它们⾃⼰的指令。
隐性汉肯句⼦是⾃证明的,但关于它们的证明却什么也没说出来——它们类似于⾃组装病毒;显性汉肯句⼦指⽰了⾃⼰证明的构造——这类似于在复制⾃⼰的过程中指挥主体细胞的那些⽐较复杂的病毒。
接应前奏:???没看懂这个概念还能引导我们走向⼀个奇怪的⽅向,如在《⼀位烟⺠富于启发性的思想》中所看到的那样。在那⾥,我们看到螃蟹如何利⽤这样⼀种思想:⾃组装信息可以四下散开,而不集中在⼀处。他希望这能防⽌他的唱机毁于乌⻳的破坏⼿段。不幸的是,正像那些最最精致的公理模式⼀样,⼀旦这个系统建⽴起来并“梳理”完毕,它的良定义性就使它要受到⼀个⾜够聪明的“哥德尔化算⼦”的攻击,而这就是螃蟹所讲的那些令⼈伤⼼的故事。
28、两个突出的问题:分化与形态发⽣
DNA 如果仅仅能指挥在细胞中合成⼀些蛋⽩质,它⼜怎么能如此惊⼈准确地控制宏观⽣物的严格结构和功能呢?⼀个是细胞分化的问题:如何区分具有同样的DNA 却⼜扮演不同⻆⾊的细胞——例如肾细胞、⻣髓细胞、脑细胞?另⼀个是形态发生的问题。局部⽔平上的细胞间的相互作⽤,如何导致⼤规模的、总体的结构和组织——诸如⾝体的各个器官、⾯貌、脑的各个部位等等?
29、反馈和前馈,阻遏物和诱导物
- 否定性的前馈或反馈。⼀种⽅法是阻⽌有关的酶起作⽤——也就是说“堵住”它们的活性部位。这叫做抑制。另⼀种⽅法是⼲脆不让有关的酶产⽣!这叫做阻遏。 操纵子。
⼀个操纵基因就是对紧挨在它后⾯的基因进⾏控制的部位,它后⾯的基因则称为操纵⼦。
- 肯定性的前馈和反馈⼜怎么样呢?仍有两种可能:(1) 释放受阻的酶,(2) 停⽌对有关操纵⼦的阻遏。使阻遏受到阻遏的机制要⽤到⼀类分⼦,称为诱导物。
(应当注意到⼤⾃然多么喜欢双重否定!这可能有着⼗分深刻的道理。)
31、反馈与怪圈的对⽐
(可讨论)抑制和阻遏在某种意义上讲,两者都是“反馈”,但后者要⽐前者深刻得多。当诸如⾊氨酸或异亮氨酸这样的⼀个氨基酸(以诱导物的形式)拴住它的阻遏物起着反馈作⽤,从而使其更多的副本得以制造的时候,它并没有说出如何构造它⾃⼰。它只是通知酶去制造那些副本。这可以与收⾳机的⾳量作个⽐较。当声⾳注⼊听者的耳朵时,有可能导致⼈去减小或增⼤⾳量本⾝。但这与⼴播本⾝命令你打开或关掉收⾳机——或者要你调到另⼀个波⻓上,或者,甚⾄是教你如何组装另⼀台收⾳机——相⽐,是完全不同的两码事!后⾯的这些事更像是各种不同的信息层次之间的那种兜圈⼦。因为此时收⾳机信号中的信息被“解码”并翻译成⼼智上的结构。收⾳机的信号是⼀些符号构成物,是这些符号的意义在起作⽤——这时是使⽤,而⾮谈论。另⼀⽅⾯,当声⾳太响时,这些符号就不是在传达意义。它们只被看作很响的声⾳,因而等于没有意义——这时是谈论,而⾮使⽤。这种情形就更像蛋⽩质调整其合成速率所使⽤的反馈圈⼦了。
32、分化的两个简单例⼦
33、细胞中的层次混合
我们来试着⽤计算机科学的术语总结⼀下给细胞的各个⼦单元分类的各种⽅法。
(1)DNA。由于DNA包含着构造作为该细胞的活性物质的各种蛋⽩质的全部信息,所以可以把DNA 看成是⽤⼀种⾼层语⾔写出、随后⼜被翻译(或解释)成细胞“机器语⾔”的⼀个程序。
另⼀⽅⾯,DNA 本⾝⼜是受各种酶操纵的被动的分⼦,在这个意义上,DNA 分⼦⼜恰像⼀⻓段数据。第三,DNA 包含着能⽣成tRNA“单词卡⽚”的模板,这意味着DNA 也含有它⾃⼰的⾼层语⾔的定义。
(2)蛋⽩质。蛋⽩质是活性分⼦,并执⾏细胞的全部功能,所以,把它们看成⽤“细胞的机器语⾔”写成的程序(细胞本⾝做为处理机)就⼗分合适。另⼀⽅⾯,由于蛋⽩质是硬件,而⼤多数程序是软件,所以把蛋⽩质看成处理机也许更好⼀些。第三,蛋⽩质经常受到其它蛋⽩质的作⽤,这意味着蛋⽩质经常是数据。最后,还可以把蛋⽩质看作解释程序,这时是把DNA 看成⼀组⾼级语⾔程序,在这种情形中,酶只是在执⾏DNA 密码写下的程序,也就是说蛋⽩质起解释程序的作⽤。
(3)核糖体及tRNA 分⼦。它们是从DNA 到蛋⽩质的翻译媒介,这种翻译可以⽐拟成⼀个程序从⾼级语⾔到机器语⾔的翻译过程。换句话说,核糖体有解释程序的功⽤,而tRNA 分⼦规定了⾼级语⾔的定义。不过,对这个翻译过程还有⼀种看法:核糖体是处理机而tRNA 是解释程序。
34、⽣命的起源
“它们怎么开始的呢?”
也许体味这种惊奇和敬畏⽐有⼀个答案更令⼈满意——⾄少暂时是这样。